Gemini 3.1 Flash-Lite が Google の最速かつ最もコスト効率の高い Gemini 3 モデルとして発売
<本文>
Google は、Gemini 3.1 Flash-Lite を発表しました。同社によれば、これはこれまでの Gemini 3 シリーズの中で最も高速で最もコスト効率の高いモデルです。本日より、Gemini 3.1 Flash-Lite は、Gemini API を介して Google AI Studio を通じて開発者向けにプレビュー版として公開されます。企業のお客様も Vertex AI を通じてアクセスできます。
大量の開発者の需要に合わせて設計されたコスト効率の高いモデル
Google は、入力トークン 100 万あたり 0.25 ドル、出力トークン 100 万あたり 1.50 ドルで、Gemini 3.1 Flash-Lite をスケールファーストのモデルとして位置付けています。同社はさらに、人工分析ベンチマークに基づいて、最初のトークンまでの時間が 2.5 倍速く、Gemini 2.5 フラッシュよりも優れたパフォーマンスを示し、出力速度が 45% 高速であると付け加えています。
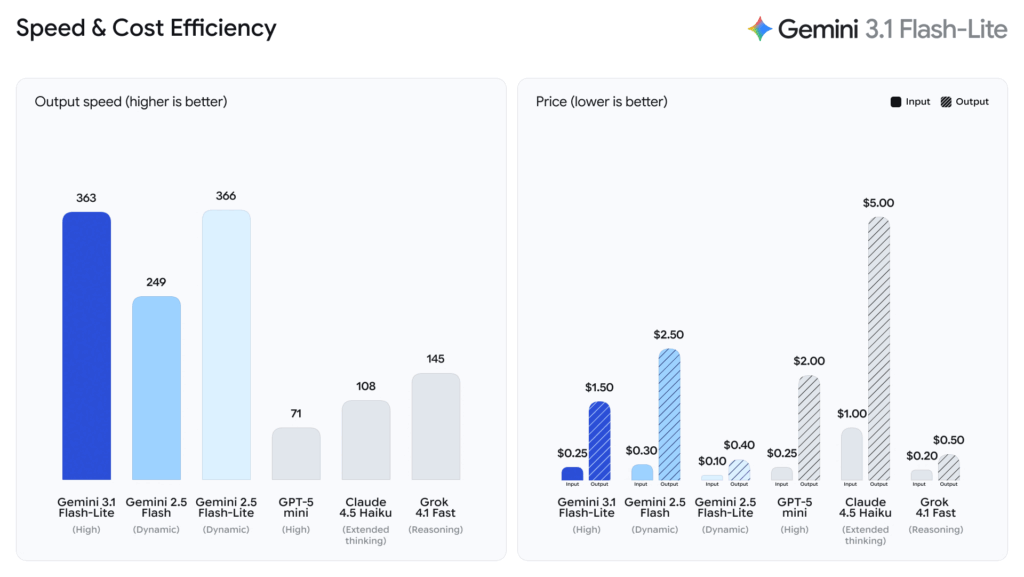 画像クレジット: Google
画像クレジット: Google
Gemini 3.1 Flash-Lite は、リアルタイム エクスペリエンスを構築する開発者向けに設計されています。インテリジェンスと同じくらいコストと遅延が重要となる、高頻度の翻訳、コンテンツのモデレーション、大規模な自動化タスクについて考えてみましょう。まあ、Flash-Lite は品質にあまり妥協していないようです。 Arena.ai リーダーボードでは 1432 を獲得し、GPQA Diamond で 86.9%、MMMU Pro で 76.8% など、強力なベンチマーク数値を記録しました。 Googleは、一部の領域では前世代の高度なGeminiモデルをも上回っていると主張している。
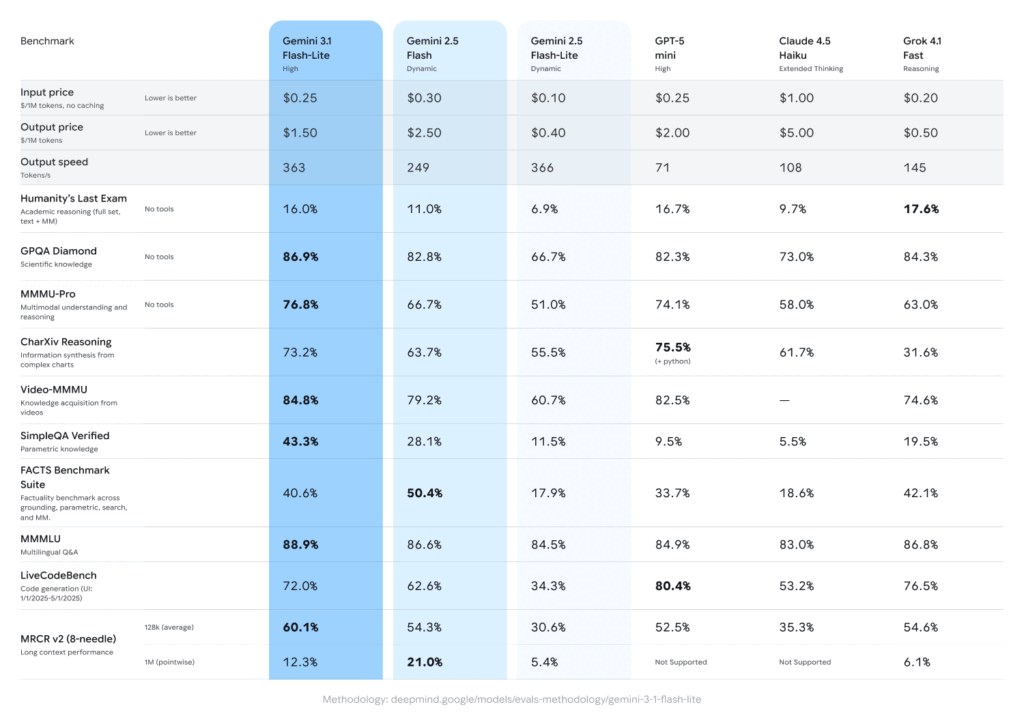 画像提供: Google
画像提供: Google
高額な値段を付けずに適応型インテリジェンスを実現
Gemini 3.1 Flash-Lite には、生の速度に加えて、AI Studio と Vertex AI 内に調整可能な「思考レベル」が含まれています。開発者は、モデルがタスクにどの程度の推論を適用するかを選択できるため、パフォーマンスを拡張しながらコストを管理できます。 Latitude や Cartwheel などの企業を含む初期のテスターは、このモデルは命令の精度を維持しながら複雑な入力を正確に処理すると述べています。 AI モデルと言えば、Microsoft が本日、OpenAI の最新 GPT-5.3 インスタント モデルを Copilot Chat と Copilot Studio に追加したことを忘れないでください。
*️⃣ 出典リンク:
Gemini 3.1 Flash-Lite を発表、Google、、Gemini モデル、、Vertex AI、また追加、GPT-5.3 Instant、