OpenAI がリアルタイム コーディング用に GPT-5.3-Codex-Spark を再リリース
<本文>
OpenAI は本日、リアルタイム コーディング用に設計された GPT-5.3-Codex の小型で速度が最適化されたバージョンである GPT-5.3-Codex-Spark のリサーチ プレビューを発表しました。これは、同社が Anthropic の Claude Opus 4.6 に対抗する GPT-5.3-Codex を発表してからわずか数日後に行われました。
特に、GPT‑5.3‑Codex‑Spark のリリースは、超低遅延ハードウェアでほぼ瞬時にコーディング結果を提供することを目的とした OpenAI と Cerebras のコラボレーションにおける最初のマイルストーンとなります。 Codex-Spark は、現実世界の開発タスクの能力を維持しながら、1 秒あたり 1000 を超えるトークンを生成できます。
速度と対話性のために最適化された Codex-Spark
以前の Codex モデルとは異なり、Codex-Spark はインタラクティブなコーディングに焦点を当てています。特定の編集を行い、ロジックを調整し、インターフェイスをリアルタイムで更新するように設計されています。このモデルには 128k トークンのコンテキスト ウィンドウがあり、現在テキストのみのインタラクションをサポートしています。ユーザーは、作業を即座に共同作業、中断、リダイレクトできるため、迅速な反復や実践的なコーディング実験に適しています。
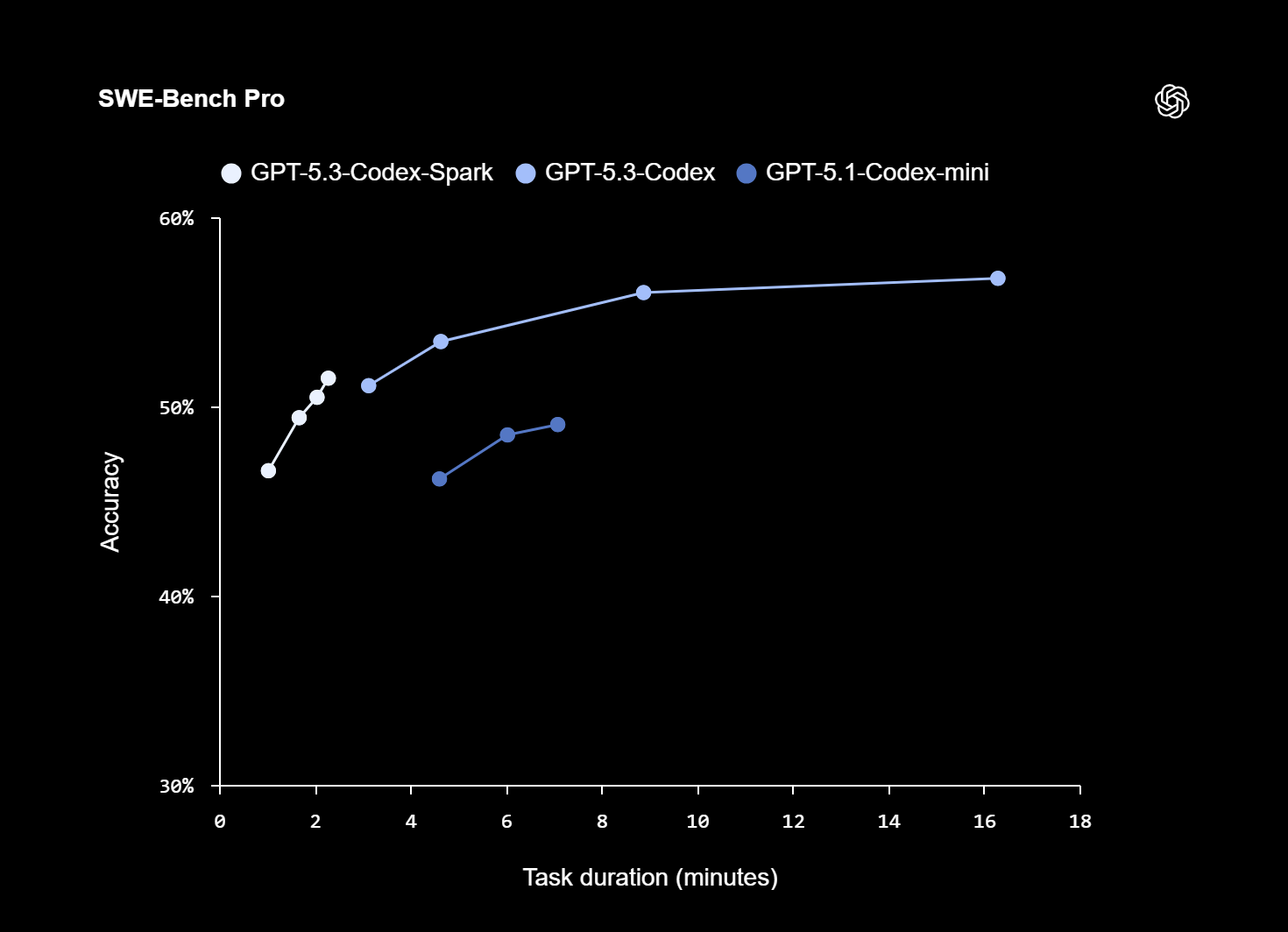
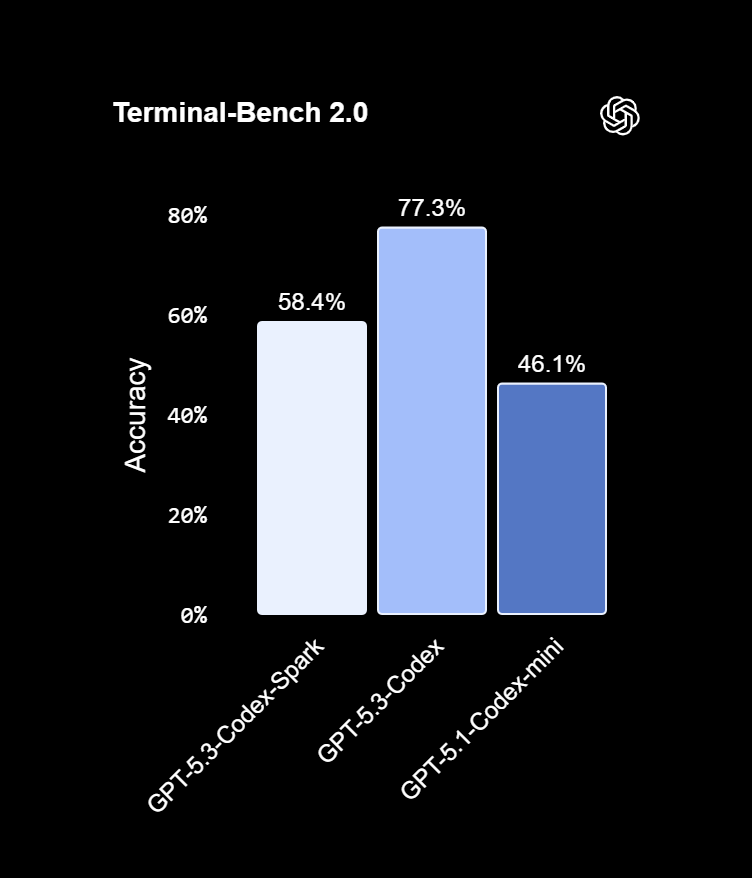
初期のベンチマークでは、Codex-Spark が強力な精度を維持しながら、前バージョンよりもはるかに速くタスクを完了することが示されています。 SWE-Bench Pro および Terminal-Bench 2.0 では、このモデルによりタスク時間が大幅に短縮され、速度の向上がトークン レベルだけでなく、要求と応答のパイプライン全体にわたって行われることが確認されました。 OpenAI はまた、WebSocket ベースの永続接続を導入し、トークンごとのオーバーヘッドを 30% 削減し、最初のトークンまでの時間を 50% 削減しました。

Cerebras を活用し、GPU インフラストラクチャを補完
Codex-Spark は、超低遅延推論専用の AI チップである Cerebras の Wafer Scale Engine 3 上で実行されます。 GPU はトレーニングと幅広い用途の中心であり続けますが、Cerebras は最小限の遅延が最も重要なワークフローを処理します。 Cerebras の CTO である Sean Lie 氏は、このモデルが開発者のワークフローを再構築し、新しい対話パターンとユースケースを導入する可能性を強調しました。
ChatGPT Pro ユーザー向けのリサーチ プレビューとして現在利用できる Codex-Spark には、プレビュー中に別のレート制限が付いています。さらに、OpenAI は、安全対策を講じながら、アクセスを段階的に拡大し、ユーザーのフィードバックを統合してモデルのリアルタイム機能を改良する予定です。
*️⃣ 出典リンク:
GPT‑5.3‑Codex‑Spark の研究プレビュー、GPT-5.3-Codex、Claude Opus 4.6、