OpenAI、Thinking と Pro のバリエーションを備えたこれまでで最も「機能的な」モデルである GPT-5.4 を発表
<本文>
OpenAI は GPT-5.4 を発表しました。GPT-5.4 は、同社がこれまでプロの仕事向けに最も有能で効率的なフロンティア モデルと呼んでいます。新しいモデルには、標準モデル、GPT-5.4 Thinking と呼ばれる推論重視のバリアント、GPT-5.4 Pro というラベルの付いた高性能オプションなど、さまざまなワークロード向けに設計された複数のバージョンが含まれています。
この発表では、内部の主要なアップグレードも強調されています。開発者にとって、GPT-5.4 の API バージョンは、100 万トークンものコンテキスト ウィンドウをサポートするようになりました。これは、OpenAI がこれまでに提供した最大のコンテキスト容量です。同社は、新しいモデルは GPT-5.2 よりも大幅に少ないトークンを使用しながら同じ問題を解決できると述べ、大規模なワークロードで顕著な効率の向上を指摘しています。
ベンチマークはナレッジワークの大幅な向上を示しています
OpenAI によれば、GPT-5.4 は現実世界のタスクに焦点を当てたいくつかの評価ベンチマークにわたって優れた結果を提供します。このモデルは、コンピュータの対話能力を測定する OSWorld-Verified および WebArena Verified で記録的なスコアを達成したと報告されています。また、ナレッジ ワーク タスクのパフォーマンスを測定するために設計された OpenAI の GDPval ベンチマークでも 83% のスコアを獲得しました。
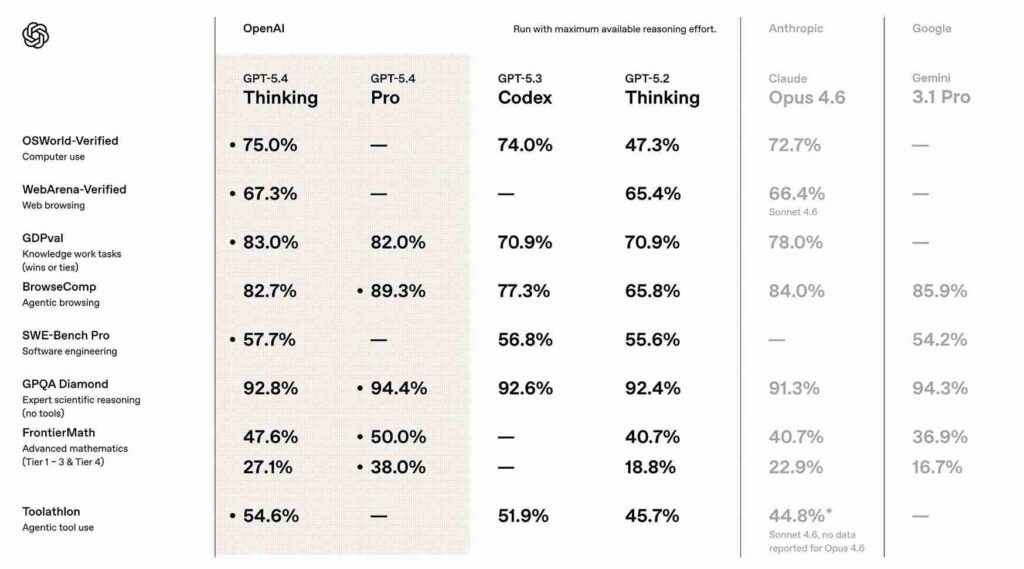 画像クレジット: OpenAI
画像クレジット: OpenAI
もう 1 つのベンチマーク結果は、財務や法律などの分野の専門スキルに焦点を当てた Mercor の APEX-Agents 評価から得られます。 GPT-5.4 は、スライドデッキ、財務モデル、法的分析など、長い形式の成果物を作成する場合にも特に優れたパフォーマンスを発揮するようです。
OpenAIはまた、新モデルにより信頼性が向上すると述べている。 GPT-5.2 と比較して、GPT-5.4 は不正確な主張を行う可能性が 33% 低く、全体的な回答に事実誤認が含まれる可能性が 18% 低くなります。
モデルの発表と並行して、OpenAI は GPT-5.4 API がツール呼び出しを処理する方法も更新し、Tool Search と呼ばれる新しいシステムを導入しました。システム プロンプトですべてのツールの定義を読み込むのではなく、モデルは必要な場合にのみツールの詳細を取得できるようになりました。この変更により、トークンの使用量が削減され、大規模なシステムをより速く、より安価に実行できるようになります。
*️⃣ 出典リンク:
OpenAI、
GPT-5.4 を発表 、
100 万トークンものコンテキスト ウィンドウをサポート 、
いくつかの評価ベンチマークにわたって強力な結果を提供、、